Web developers maken steeds vaker gebruik van JavaScript. Frameworks als Angular, Ember, Node en Vue zijn de afgelopen jaren enorm in populariteit toegenomen. Vanuit de gebruikerservaring terecht. Je kan er prachtige dynamische applicaties mee ontwikkelen. De architectuur van deze nieuwe frameworks is onderhoudsvriendelijk, modern en biedt frontend mogelijkheden om steeds meer de interactie met de bezoeker aan te gaan. Voorbeelden van populaire websites zijn Netflix, PayPal, Dropbox & Facebook.
Er kleven alleen wel nadelen aan het gebruik van JavaScript frameworks. Ondanks dat ze steeds populairder worden, hebben zoekmachines de grootste moeite om te begrijpen wat er op deze websites staan. Wanneer content voor een zoekmachine niet bereikbaar is, heeft dit drastische gevolgen voor de organische vindbaarheid. In dit blog vind je informatie over hoe een zoekmachine omgaat met JavaScript frameworks en welke oplossingen er zijn om jouw website zoekmachine vriendelijk te maken.
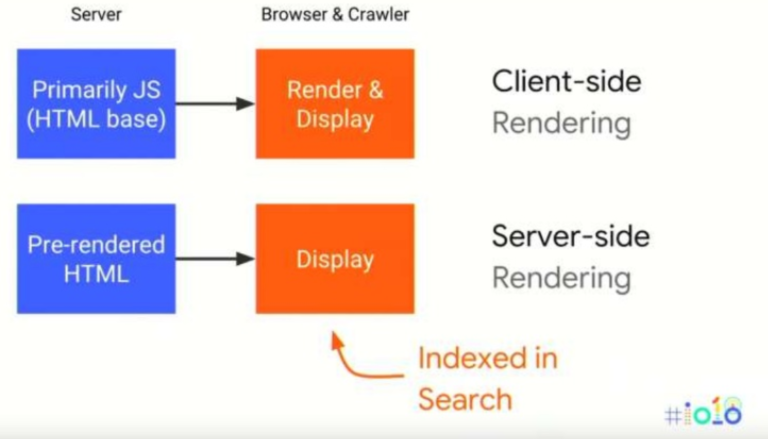
Server side rendering versus client side rendering
Het proces waarbij de browser of bot een HTML bestand ontvangt en direct toegang heeft tot de content wordt server-side rendering genoemd. Platte HTML die door de server wordt geleverd kan razendsnel worden opgepakt door een bot.
Bij client side rendering wordt de content gerenderd in de browser door middel van JavaScript. De bot ontvangt een haast leeg HTML document met JavaScript.
bron: Google IO 2018
Als voorbeeld nemen we een standaard Angular framework. Wellicht vraag je je af hoe dit een probleem kan zijn voor zoekmachines. Er staat simpelweg een titel, een afbeelding en wat links.
Wanneer je echter kijkt naar de broncode en de initiële HTML die door de server wordt geleverd, wordt het duidelijk dat nergens de content en links terugkomen. In de body van het document is alleen de app-root en een aantal scripts zichtbaar. De titel, afbeeldingen en links zijn nergens te bekennen. Enkel JavaScript. Het crawlen en indexeren is dus niet voldoende voor een zoekmachine om te bepalen wat er nu op een website staat. Googlebot gebruikt daarom een eigen web rendering service (WRS) voor het renderen van JavaScript. Op deze manier kan Google content en links achterhalen die nodig zijn voor het indexeren.
Hoe gaat Google om met JavaScript?
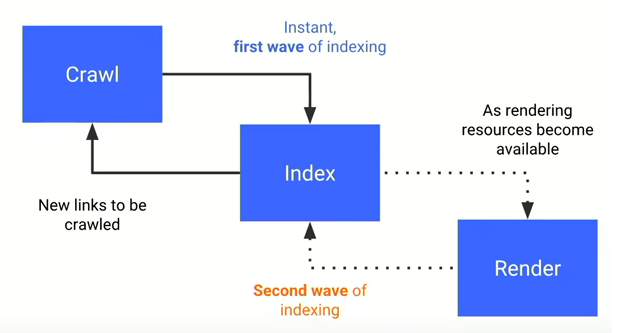
Onderstaande afbeelding geeft weer hoe het indexatieproces van Google werkt.
bron: Google IO 2018
De eerste ronde van indexatie is het standaard proces voor elke website. Googlebot crawlt de ruwe HTML van een webpagina en voegt gevonden links toe aan een crawllijst.
De gecrawlde pagina’s worden verwerkt in de index (Google Caffeïne Indexer)
Wanneer tijdens het indexeren blijkt dat er Javascript bestanden gerenderd moeten worden, gaat de volledige indexatie pas verder wanneer Googlebot dit mogelijk acht en wordt een voorlopige versie geserveerd in de index.
Googlebot stelt het renderen uit tot de volledige bronnen beschikbaar zijn. Deze bronnen zijn afhankelijk van hoe Google de kwaliteit van je website beoordeelt (E-A-T) en wat het crawlbudget (ofwel renderingbudget!) is.
Wanneer genoeg resources beschikbaar zijn, wordt de pagina gerenderd en wordt de nieuwe beschikbare content beoordeeld en geïndexeerd.
Het parsen, omzetten en uitvoeren van JavaScript kost veel computerkracht en dus tijd voor een bot. In het geval van een JavaScript-rijke website moet Googlebot het renderingproces dus steeds herhalen om content en nieuwe links te bereiken. Deze vertraging kan ervoor zorgen dat niet alle pagina’s op de website de tijd krijgen om geïndexeerd te worden. Extra vervelend is dit wanneer content op de website dagelijks wordt geüpdatet en actualiteit een grote rol speelt. De kans is aanwezig dat Google door het gebruik van JavaScript belangrijke componenten als content, interne links, meta tags (canonicals, meta robots) http statuscodes en structured data niet juist oppakt.
Ziet Google mijn content?
Googlebot gebruikte voorheen een oude browserversie (Chrome 41) voor het renderingproces. Dit betekent dat content die voor gebruiker zichtbaar is, niet altijd te begrijpen was voor een zoekmachine. Elementen die niet werden ondersteund door Chrome 41 zijn niet bereikbaar voor Googlebot.
Sinds mei 2019 heeft Google aangegeven hun web rendering service (WRS) evergreen te houden. Dit betekent dat wanneer er een nieuwe versie van Google Chrome uitkomt, hun WRS ook in deze nieuwste versie beschikbaar is. In theorie betekent dit dat de nieuwste JavaScript features gerenderd worden door Google.
De manier om te achterhalen of jouw content zichtbaar is voor Google is door dit te testen in Chrome Developer Tools. Bekijk of of de tekst op jouw webpagina binnen het DOM wordt weergegeven (ctrl-f en de tekst plakken). Wanneer de content binnen het DOM wordt weergegeven moet Googlebot in staat zijn de content te herkennen na het renderen. Het Document Object Model (DOM) is een API voor gestructureerde HTML en XML documenten. In de inhoud van het DOM was vroeger vooral statische HTML zichtbaar. Tegenwoordig wordt er veel meer gebruik gemaakt van dynamische HTML. Doordat het mogelijk is om de inhoud te wijzigen aan de hand van HTML, CSS en JavaScript, verandert de content binnen het DOM continu. Denk hierbij aan nieuwe producten die telkens worden vervangen op een pagina. De content op deze pagina verandert dan ook voortdurend terwijl de URL hetzelfde blijft.
Google is voorloper in het renderen en ‘begrijpen’ van JavaScript. Er zijn echter meer bots dan alleen Googlebot. Denk aan Bingbot, Facebookbot, Twitterbot en verschillende tools. Veel van deze tools crawlen geen JavaScript. Schakel JavaScript uit om te testen of content zichtbaar is voor een bot. Dit kan eenvoudig met een extensie als Web Developer Tools.
Maak je JavaScript website zoekmachinevriendelijk
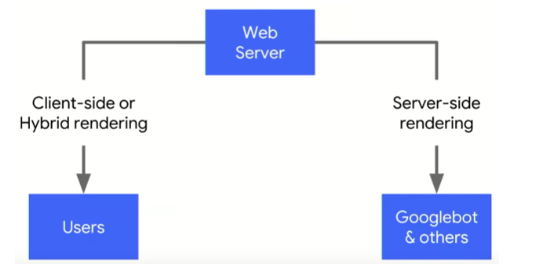
Google geeft zelf in officiële bronnen aan dat bots moeite hebben met JavaScript en komt met een oplossing: dynamic rendering. Dynamic rendering is een manier om JavaScript websites goed te laten werken met Google Search. De webserver bekijkt of een server request wordt gedaan door een gebruiker of door een bot. Op basis van deze input wordt client side content naar gebruikers gestuurd en server side content naar crawlers.
bron: Google developer tools
Bij de implementatie van dynamic rendering wordt bij een aanvraag van een crawler gebruik gemaakt van een tussenstap (middleware). Deze tussenstap zorgt dat voor client side content een statische HTML pagina wordt geserveerd (prerendered). Deze tussenstap wordt door een dynamische renderer gedaan. Een voorbeeld van een dynamische renderer die wordt aanbevolen door Google is Rendertron. Met Rendertron kan je aangeven welke bots statische HTML moeten ontvangen. Ook kan je onderscheid maken of je dynamic rendering wil gebruiken voor de hele website of enkele pagina’s.
Bron: Google IO 2018
Let wel op: dynamic rendering is een workaround en creëert twee structuren in plaats van één. Het is gemaakt voor zoekmachines.
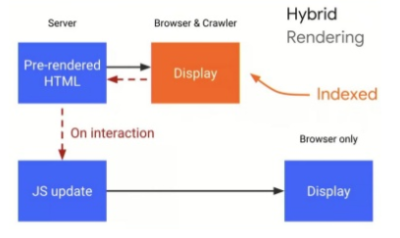
Hybrid rendering
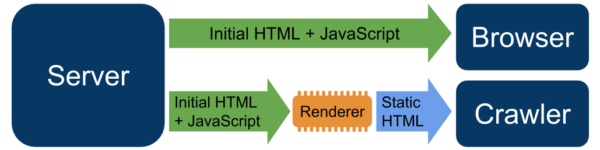
Een andere oplossing is hybrid rendering. Hybrid rendering is een methode waarbij tijdens de eerste indexeringsgolf content server side wordt aangeboden en daarna client side JavaScript. Enkele voorbeelden van technologieën die dit mogelijk maken zijn Angular Universal voor Angular, Next js voor React en Nuxt js voor Vue.
Bron: Google IO 2018
Wanneer gebruik ik dynamic/server side/hybrid rendering?
Gebruik prerendering/server side rendering in de volgende gevallen:
Grote websites met veel JavaScript waarbij de snelheid van indexatie cruciaal is.
Websites met een moderne JavaScript library. Netflix verwijderde onnodige client side React JavaScript en plaatste dit server side. Dit resulteerde in een 50% betere performance op de landingspagina.
Websites waarbij content erg afhankelijk is van social media. Zo kan je user agents als facebookbot en linkedinbot statische HTML serveren, waardoor deze content sneller geïndexeerd wordt.
Let er bij het gebruik van server side rendering extra op dat:
De belangrijkste content zichtbaar is voor een zoekmachine. Let daarbij extra op load events en user events. Het load event wordt afgevuurd door de browser wanneer de site compleet geladen is. Dit maakt het mogelijk voor zoekmachines om een snapshot te maken van de gerenderde content. Events die worden geladen na het load event worden niet geïndexeerd omdat JavaScript content kan veranderen. Na het load event kunnen er verdere user events worden getriggerd via JavaScript. Denk hierbij bijvoorbeeld aan content achter clicks of interactieve navigatie en infinite scroll. Deze content wordt normaal gesproken niet geïndexeerd door zoekmachines omdat deze plaatsvinden ná het load event.
De zoekmachine eenvoudig links, meta titels, descriptions, canonicals, hreflang, robots, kopjes en alt attributen kan vinden.
Structured data server side zichtbaar is en niet binnen een JavaScript element staat. Plaats bij voorkeur de structured data in de head van de HTML broncode.
URL’s zo clean mogelijk zijn, een duidelijke structuur hebben en geen parameters of hashes bevatten.
Links duidelijk zijn opgemaakt met het <a href </a> altribuut:<a href=”/je link”>Wordt gecrawled</a> <a href=”/je link” onclick=”changePage(‘good-link’)”>Wordt gecrawled</a> <span onclick=”changePage(‘je link)”>Wordt niet gecrawled</span> <a onclick=”changePage(‘je link)”>Wordt niet gecrawled</a>
Meer weten over dit onderwerp, bekijk dan hier de video:
Ga aan de slag met SEO
JavaScript heeft als programmeertaal vele voordelen en biedt de mogelijkheid om de interactie met de gebruiker aan te gaan. Wanneer deze interactie niet mogelijk is omdat de website niet toegankelijk is voor zoekmachines, gaat dit ten koste van de online vindbaarheid en de omzet. JavaScript is complex voor zoekmachines en het is een uitdaging om JavaScript frameworks goed te laten werken met search. Developers en SEO specialisten kunnen ontzettend veel van elkaar leren op dit gebied en wij moedigen het aan om samen met developers de website zo optimaal mogelijk te laten presteren. SDIM helpt websites aan een betere online vindbaarheid. Mocht je meer willen weten over dit onderwerp of wil je een betere online vindbaarheid, neem dan contact met ons op!
Daan is een ervaren specialist met passie voor complexe technische vraagstukken. Als lid van de Commissie Search bij branchevereniging DDMA draagt hij z’n steentje bij aan het zoekmachinemarketing landschap in Nederland.