Technische SEO, een bekend begrip, waar in veel gevallen weinig mee gedaan wordt. Toch is het naar onze mening een van de belangrijkste aspecten van SEO, en vormt het zelfs de basis voor alle andere SEO activiteiten. Wat technische SEO is en waarom ieder bedrijf het nodig heeft om organisch vindbaar te zijn met de website, leggen we in dit artikel uit.
Drie SEO pijlers
Zoals je misschien al weet, bestaat SEO uit drie pijlers: content, autoriteit en techniek. Deze derde en laatste pijler zien wij regelmatig achterblijven op de rest. Bedrijven hebben namelijk vaak geen of onvoldoende kennis van de technische kant van SEO. Met als gevolg dat het laag op de agenda komt te staan.
Dit, terwijl technische SEO de basis vormt voor al het andere. Want bouwen aan een website zonder een sterke basis is zonde, toch?
Waarom is technische SEO belangrijk?
Het succes van een website valt of staat met de techniek. Een technisch sterke website presteert beter in de zoekresultaten. Dit betekent meer organisch bezoek aan je site én meer bezoekers met de kans om te converteren, betekent doorgaans meer omzet.
Het tegenovergestelde is ook waar: een technisch slechte website heeft een negatieve invloed op de organische resultaten van de website. Technische gebreken of fouten kunnen er namelijk voor zorgen dat de website slecht vindbaar is. Of in het ergste geval: dat de website of een gedeelte hiervan zelfs helemaal niet wordt vertoond in de zoekresultaten. Alle overige inspanningen, bijvoorbeeld op het gebied van content en autoriteit, hebben in dat geval geen zin. Want je kunt schrijven wat je wilt, maar als een pagina niet opgenomen wordt in de indexatie, dan zal niemand je content lezen.
Naast het goed mogelijk maken om je website te laten indexeren, is het ook erg belangrijk dat je website snel en veilig is. Google en andere zoekmachines stellen gebruikservaring voorop. Dat betekent dat een slecht te navigeren of traag ladende website slechter zal scoren dan een website die makkelijk te navigeren en snel is. En een onbeveiligde website zal al helemaal slecht scoren, want wanneer je gegevens gestolen kunnen worden bied je nu niet bepaald een goede gebruikservaring.
Bovenstaande punten zijn de reden dat het van groot belang is dat een website op de juiste manier SEO technisch geoptimaliseerd is voor de opname in de zoekresultaten.
Technische SEO analyse
Om de in de volgende hoofdstukken beschreven punten te achterhalen, is er een technische SEO analyse nodig. In deze analyse probeer je te achterhalen wat er allemaal nog niet goed gaat in de website. Want als je niet weet wat er mis is, kun je ook niet optimaliseren.
Na de technische SEO analyse kun je vervolgens een plan opstellen, wij noemen dat een ‘roadmap’. Hierin geef je prioriteit aan bepaalde belangrijke punten en zet je alle actiepunten in een planning. Technische SEO optimaliseren kan veel tijd kosten, dus het is goed om de punten op te delen in ‘must haves’ en ‘nice to haves’. Je optimaliseert dan eerst de absoluut noodzakelijke punten, is er dan aan het eind van het traject tijd over? Dan kun je de nice to have punten nog oppakken.
Technische SEO analyse tools
Voor het uitvoeren van een technische SEO analyse kun je verschillende tools gebruiken. Hieronder vind je een overzicht van onze favoriete SEO tools en waar ze voor gebruikt worden:
Screaming frog: een erg complete tool. Hiermee kun je je hele website crawlen, zelfs als deze nog in een ‘staging omgeving’ staat, of op ‘noindex’. De tool geeft je inzichten in de fouten op je website. De tool kan middels API’s gekoppeld worden met enkele andere tools uit deze lijst, voor een nóg completer overzicht.
Google Search Console: deze tool van Google zelf is je misschien al bekend. GSC geeft je inzicht in de prestatie van je website a.d.h.v. rapporten. Je kunt hierin veel data analyseren, tot wel 16 maanden terug. Ook kun je de indexatie van je website checken en redenen achterhalen waarop bepaalde pagina’s niet geïndexeerd worden.
PageSpeed Insights: in deze tool kun je de snelheid van je website testen. De tool geeft je tips voor het optimaliseren van de snelheid. Ook geeft de tool tips over het optimaliseren voor Google’s Core Web Vitals.
Webpagetest.org: deze tool doet in principe hetzelfde als PageSpeed Insights, maar het is altijd goed om de websitesnelheid gegevens met 2 verschillende tools te testen. Reden hiervoor is dat ze soms erg verschillende output geven. Webpagetest laat ook de waterfall zien, een breakdown van alle processing die plaatsvindt tijdens het laden van een pagina.
Schema.org: deze website biedt een validator voor het valideren van de structured data op specifieke pagina’s. Ook is het een groot archief van Schema, verschillende soorten structured data. Middels de zoekfunctie kun je documentatie vinden per soort Schema.
Ahrefs: dit is een specifieke SEO tool voor o.a: linkbuilding, zoekwoordonderzoek, concurrentieanalyse, het tracken van zoekwoordposities maar ook het uitvoeren van technische SEO analyses. Deze tool is vergelijkbaar met: Semrush, SE Ranking en andere SEO tools.
Siteliner: deze tool controleert je website op duplicate content en vertelt je welke pagina’s overlap hebben a.d.h.v. een percentage. Ook rapporteert de tool dingen als gemiddelde laadtijd, hoeveelheid woorden per pagina, text tot HTML ratio en gemiddelde pagina grootte.
Chrome Dev tools: en last but not least natuurlijk Chrome Dev tools. Deze tool vind je in Chrome door op F12 te drukken en laat je de HTML/CSS achter een pagina zien. Ook zijn hier verschillende tools ingebouwd die erg handig zijn voor debugging.
Website structuur
Voordat we zelfs maar beginnen over technische SEO onderdelen, is het belangrijk om vast de website structuur te noemen. Een succesvolle website, en het technisch optimaliseren hiervan, valt of staat namelijk met de site structuur.
Een goede website structuur is belangrijk om voornamelijk twee redenen:
Een goede (navigatie) structuur verbetert de ervaring van gebruikers doordat zij makkelijker kunnen vinden wat zij zoeken. Denk bijvoorbeeld aan het header-menu, maar ook het clusteren van bepaalde content.
En met de juiste (URL) structuur help je ook de zoekmachines begrijpen hoe de website in elkaar steekt en hoe pagina’s aan elkaar gerelateerd zijn. Dit doe je door een logische opbouw van lagen (o.a. categorieën) in de URL’s, maar ook met intern linken bijvoorbeeld.
Hoe groter je website is, des te belangrijker het wordt om de website structuur goed voor elkaar te hebben. Maar ook voor kleine(re) websites is de structuur van groot belang. Wij vinden dit zo belangrijk, dat wij een heel artikel hebben gewijd aan website structuur.
Technische SEO onderdelen
Naast de website structuur zijn er natuurlijk nog veel meer factoren van belang voor het SEO technisch optimaliseren van een website. In dit hoofdstuk bespreken we de belangrijkste onderdelen.
Crawlen & indexeren
Zoekmachines crawlen het internet door gebruik te maken van een groot aantal computers met enorme kracht (processing power). Dit is nodig omdat er miljarden webpagina’s bestaan. Het Google programma dat de webpagina’s zoekt heet ‘Googlebot’, maar dit soort programma’s staan ook bekend als ‘crawler’, ‘robot’ en ‘spider’. Wanneer de link naar jouw website gevonden is, dan gaat zo’n crawler alle links af op jouw website. Daarom is een duidelijke website structuur dus belangrijk, maar er zijn nog veel meer aspecten die bijdragen aan succesvolle crawling & indexatie.
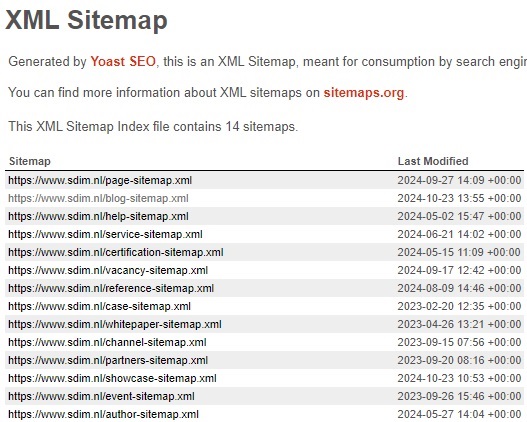
XML sitemaps
Een sitemap is een soort inhoudsopgave die crawlers kunnen gebruiken om jouw website te crawlen, en hopelijk, te indexeren. Het is een overzicht van alle URL’s die volgens jou belangrijk zijn om opgenomen te worden in de indexatie.
Het is een sitemap belangrijk om dan ook enkel de URL’s op te nemen die getoond moeten worden op de zoekresultatenpagina. Dit betekent dat de pagina’s bereikbaar moeten zijn (geen 404’s), ze de hoofdversie moeten zijn (niet canonicalized) en niet omgeleid moeten zijn (een status 3XX code moeten hebben).
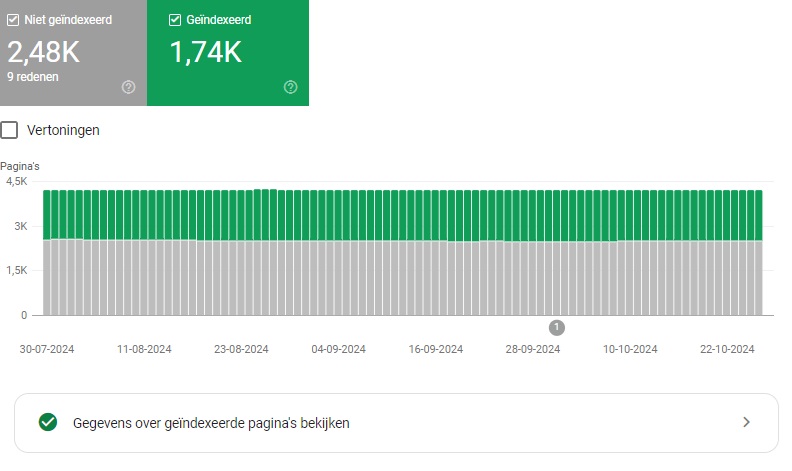
De sitemap kun je indienen in Google Search Console en in Bing Webmaster Tools. Zo help je de zoekmachines een extra handje. Ze verzamelen vervolgens alle benodigde data en geven je een overzicht van de indexatie van de URL’s in deze sitemap(s).
In GSC vind je onder Indexeren > Pagina’s, een overzicht van de wel en niet geïndexeerde pagina’s en de redenen waarom deze bijvoorbeeld niet geïndexeerd zijn. Hier kun je ook filteren op: bekende pagina’s, ingediende pagina’s, niet-ingediende pagina’s of op een specifieke sitemap. Je kunt er namelijk meer dan één indienen.
Crawl budget
Het crawlbudget verwijst naar de hoeveelheid tijd en middelen die toegewezen aan het crawlen van een website. Dit budget bepaalt namelijk hoe vaak en hoeveel pagina’s van je site door Googlebot worden bezocht en geïndexeerd.
Het is belangrijk rekening te houden met crawl budget omdat een efficiënt gebruik van het crawlbudget ervoor zorgt dat belangrijke pagina’s van je website sneller worden geïndexeerd, wat kan bijdragen aan betere zichtbaarheid in zoekresultaten. Als het crawlbudget niet optimaal wordt benut, kan het zijn dat sommige pagina’s niet of pas veel later door Google worden geïndexeerd, wat je indexatie, en dus je organische vindbaarheid, kan schaden.
Crawl budget is met name van belang bij websites met (tien-)duizenden pagina’s, of wanneer je regelmatig content toevoegt, denk bijvoorbeeld aan een nieuwsplatform.
Robots.txt
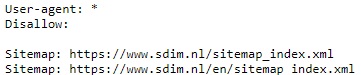
Een ander belangrijk aspect om rekening mee te houden is het gebruik van het robots.txt bestand. Dit tekstbestand wordt door webmasters ingezet om richtlijnen te geven aan bots en crawlers over welke delen van de website ze wel of niet mogen bezoeken. Ook is het goed om in dit bestand te linken naar je XML sitemap.
Je vindt het Robots.txt bestand doorgaans door /robots.txt achter het hoofddomein te typen, bijvoorbeeld:
https://www.sdim.nl/robots.txt
Het robots.txt bestand kan helpen om het crawlen van je site te stroomlijnen, maar het kan ook voor problemen zorgen als het niet goed wordt geconfigureerd.
In principe bepaalt het Robots.txt bestand welke pagina’s wel of niet geïndexeerd moeten worden door zoekmachines. Dit is nuttig wanneer je bepaalde pagina’s wilt uitsluiten van indexering, bijvoorbeeld omdat ze nog in ontwikkeling zijn of omdat ze intern concurreren met andere pagina’s (zoekwoordkannibalisatie).
Ook kun je in dit bestand bijvoorbeeld filters uitsluiten, hiermee voorkom je dat er onnodig duizenden varianten van een URL worden gecrawld.
Een voorbeeld
Stel dat je een e-commerce website hebt met een productpagina voor “Witte Sneakers”. Gebruikers kunnen verschillende filters toepassen, zoals bijvoorbeeld maat, die resulteren in verschillende URL’s:
https://voorbeeld.com/sneakers/wit
https://voorbeeld.com/sneakers/wit?maat=42
Door regels aan het Robots.txt bestand toe te voegen waarmee alle filter parameters voor ‘maat’ uitgesloten worden van crawlen, bespaar je crawl budget.
De regels kan er zo uit zien:
Disallow: /*?maat=
Het kan echter nadelig zijn als een belangrijke pagina per ongeluk wordt uitgesloten door het robots.txt bestand. Hierdoor kan het bestand zoekmachines onbedoeld de instructie geven om de pagina niet te indexeren, wat kan leiden tot verlies van zichtbaarheid in zoekresultaten. Test de regels in het Robots.txt bestand dus goed.
Noindex & nofollow tag
Naast het Robots.txt bestand zijn er ook verschillende HTML tags waarmee indexatie kan worden beïnvloed. De belangrijkste zijn de ‘noindex tag’ en de ‘nofollow tag’.
De noindex tag zorgt ervoor dat bepaalde pagina’s of secties niet worden geïndexeerd door zoekmachines, en dus getoond worden in de zoekresultaten, maar heeft geen invloed op de bereikbaarheid of het crawlen van deze pagina’s.
De noindex tag ziet er zo uit en wordt geplaatst in de <head> sectie:
<meta name=”robots” content=”noindex”>
De nofollow tag voorkomt dat zoekmachines de gelinkte pagina’s crawlen en de link meewegen in hun algoritmes voor zoekrangschikking. Dit betekent niet dat de gelinkte pagina helemaal niet wordt geïndexeerd; als de pagina ergens anders op het web wordt gelinkt zonder nofollow tag, kan deze nog steeds worden geïndexeerd.
De nofollow tag ziet er zo uit en kan per URL meegegeven worden:
Bij meertalige websites zijn hreflang tags van belang voor het correct crawlen en indexeren. Dit is omdat hreflang tags zoekmachines helpen te begrijpen welke versie van een pagina moet worden weergegeven aan gebruikers op basis van hun taal en locatie. Dit verbetert de gebruikservaring, de belangrijkste rankingfactor.
Ook zorgen deze hreflang tags ervoor dat zoekmachines verschillende taalvarianten van dezelfde content niet zien als duplicate content. Hiermee kun je een onbedoelde negatieve beoordeling voorkomen.
Hreflang tags zijn HTML code die je, net als de noindex tag, in de <head> sectie plaatst. Ze zien er zo uit:
Gebruikelijk is om ook een ‘x-default’ hreflang tag te gebruiken. Deze tag wordt gebruikt wanneer er geen specifieke taal- of regionale versie beschikbaar is die overeenkomt met de voorkeuren van de bezoeker. Het wordt vaak gebruikt als een “fallback” optie voor gebruikers die niet expliciet door andere hreflang tags worden gedekt. Vaak is dit de hoofdtaal van het land waar het bedrijf zich bevindt. Maar ook Engels is een goede optie, omdat de meeste gebruikers Engels zullen begrijpen.
Canonical tag
Canonical tags zijn HTML elementen die aan zoekmachines aangeven welke versie van een pagina de ‘voorkeur- of hoofdversie’ is wanneer er meerdere URL’s met vergelijkbare of identieke inhoud (content) zijn. Dit helpt zoekmachines om te voorkomen dat ze duplicaten van dezelfde inhoud indexeren, hiermee bespaar je op crawl budget en voorkom je ook onbedoelde negatieve beoordeling.
Een canonical tag ziet er als volgt uit en wordt in de <head> sectie geplaatst:
Stel dat je een e-commerce website hebt met een productpagina voor ‘zwarte leren handtas’. Gebruikers kunnen dezelfde content benaderen via verschillende URL’s:
Hoewel de inhoud van deze pagina’s grotendeels hetzelfde is, kunnen zoekmachines deze als aparte pagina’s beschouwen, wat leidt tot (technische) duplicate content.
Door een canonical tag toe te voegen aan alle varianten van deze pagina’s, kun je aangeven welke versie de voorkeursversie is die geïndexeerd moet worden. In dit geval kan de hoofdversie bijvoorbeeld zijn:
Zoals we eerder al noemden stellen zoekmachines gebruikservaring voorop. Dat is dan ook waarom website snelheid en Google’s Core Web Vitals een grote rol spelen. Want een trage website waar elke pagina 10 seconden moet inladen en alle elementen verspringen tijdens het scrollen, staat nu niet bepaald gelijk aan een fijne gebruikservaring.
Website snelheid en voldoen aan de Core Web Vitals (CWV) hebben dus direct invloed op de organische prestaties van je website. Natuurlijk blijft het belangrijk om ook goede content te schrijven en moet je werken aan je autoriteit (backlinks hebben nog steeds een grote invloed). Maar al deze aspecten hebben elkaar nodig om goed te kunnen presteren.
In ons uitgebreide artikel over website snelheid lees je meer over wat je kunt doen om de snelheid te optimaliseren. Ook lees je hier over wat Google’s Core Web Vitals precies zijn en hoe je hiervoor kunt optimaliseren.
Toch geven we je hier vast een paar korte tips:
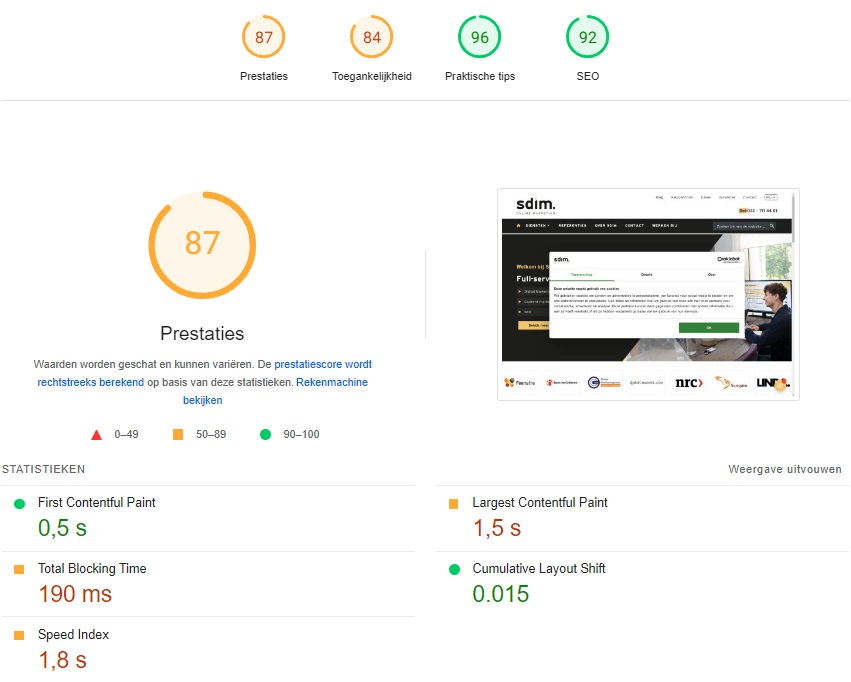
Gebruik een tool als PageSpeed Insights voor het analyseren van de snelheid
Onder het kopje ‘Ontdek wat je echte gebruikers ervaren’ zie je of de pagina voldoet aan de CWV’s
Onderaan bij het kopje ‘diagnostische gegevens’ zie je vervolgens welke aspecten de laadtijd vertragen
Veelvoorkomende oorzaken van vertraging zijn:
JavaScript uitvoeringstijd
Te groot LCP-element (vaak is dit de hero-banner)
Te grote afbeeldingen
Code van derden, bijvoorbeeld plugins
Zoekwoord kannibalisatie & duplicate content
Wanneer je vanaf dag 1 werkt met een duidelijke contentstrategie en iedereen binnen de organisatie zich hieraan houdt, dan zal er weinig duplicate content en zoekwoord kannibalisatie optreden. Helaas is dit in veruit de meeste gevallen een idealistisch scenario, en ligt het in de realiteit anders.
Misschien bestaat je site al jaren en had je geen idee van technische SEO, duplicate content of SEO in het algemeen. Dan is het goed mogelijk dat je website vol staat met duplicate content, en last heeft van zoekwoord kannibalisatie. Maar ook als je site nieuw is, en je je wél aan een contentstrategie houdt is het moeilijk om dit te voorkomen. Duplicate content en zoekwoord kannibalisatie weten altijd hun weg naar jouw website te vinden.
Want zelfs als je je heel bewust bent van duplicate content tijdens het schrijven van teksten en maken van pagina’s, bestaat er ook nog zoiets als ‘technische duplicate content’. Wij gaven hiervan al een voorbeeld van bij het stukje over de canonical tags. Deze soort duplicate content zie je gauw over het hoofd, en is bij bijvoorbeeld e-commerce websites vaak ook niet te voorkomen. Zorg er dus altijd voor dat je ook de filterparamaters, UTM-tags en alle eerdergenoemde HTML tags goed naloopt.
Zoekwoord kannibalisatie hebben we nog niet echt uitgelegd; dit treedt op wanneer meerdere pagina’s op dezelfde website gericht zijn op hetzelfde zoekwoord of een erg vergelijkbaar zoekwoord. Dit kan ertoe leiden dat deze pagina’s met elkaar gaan concurreren in de zoekresultaten van zoekmachines, wat de zichtbaarheid van deze pagina’s kan verminderen, doordat zij minder hoog in de zoekresultaten voor komen.
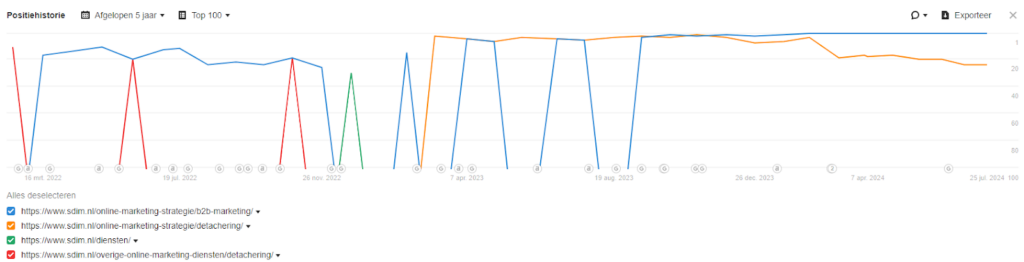
In plaats van één sterke pagina die goed scoort, zorgt zoekwoord kannibalisatie ervoor dat de relevantie en autoriteit over meerdere pagina’s verspreid wordt, waardoor ze allemaal lager kunnen scoren. In het voorbeeld hieronder zie je goed hoe de pagina met de blauwe lijn steeds wordt verstoten door de pagina met de oranje lijn:
Verschillende oplossingen kunnen zijn:
Beide pagina’s samenvoegen tot één sterke ‘content pilaar’ dat alle informatie biedt over een bepaald onderwerp
Content op beide pagina’s herschrijven, waarbij ze beide specifieke zoekwoorden targetten die geen overlap met elkaar hebben
Moet je het zoekwoord toch noemen, dan kun je middels interne linking ook aangeven dat een andere pagina belangrijk is voor dat zoekwoord
Een van de pagina’s offline halen en redirecten
Een van de pagina’s een noindex tag geven
De meest geschikte oplossing is erg situatieafhankelijk. Met name de laatste twee punten, dit zijn vrij extreme oplossingen. Kijk hierbij goed naar wat voor soort pagina het is, verkeer, conversie en wat het belang is van de pagina voor jouw organisatie.
Veiligheid
De meeste websites voldoen tegenwoordig aan deze vereiste, maar het is te belangrijk om het niet te benadrukken. Het is belangrijk om je website te beveiligen met HTTPS omdat het de gegevensuitwisseling tussen je website en de bezoekers versleutelt. Dit beschermt gevoelige informatie, zoals inloggegevens en betaalgegevens, tegen onderschepping door kwaadwillenden.
Daarnaast verhoogt HTTPS het vertrouwen van bezoekers in je site, aangezien browsers beveiligde websites aangeven met een slotje in de adresbalk.
Bovendien beschouwen zoekmachines HTTPS als een ranking factor, wat betekent dat een beveiligde website betere kansen heeft om hoger in de zoekresultaten te verschijnen. Kortom, maak het jezelf niet onnodig lastig, en zorg dat je website gebruik maakt van HTTPS.
Structured data
Structured data is een gestandaardiseerde manier om informatie over je website te markeren, zodat zoekmachines deze beter kunnen begrijpen. Door gebruik te maken van schema.org, kun je specifieke details zoals producten, evenementen, recensies veelgestelde vragen en meer duidelijk aan zoekmachines presenteren.
Het is belangrijk voor SEO omdat het zoekmachines helpt om de inhoud van je pagina’s beter te interpreteren en weer te geven in de zoekresultaten. Dit kan resulteren in ‘rich snippets’, zoals sterrenbeoordelingen of productprijzen, die je zichtbaarheid vergroten en de klikfrequentie naar je website verbeteren. Structured data draagt zo bij aan een betere gebruikerservaring en kan je helpen hoger te ranken in de zoekresultaten.
In ons uitgebreide artikel lees je alles wat je wilt weten over structured data.
Technische SEO fouten elimineren
Zoals je hebt gelezen is technische SEO van groot belang voor de organische resultaten van elke website. Want zonder sterk technisch fundament, heeft het weinig zin om aan je website te bouwen.
We starten daarom met een technische SEO analyse, waarna de daaruit voortvloeiende punten omgezet worden in een roadmap. Aan de hand van deze roadmap kun je stap voor stap elk probleem aanvliegen. Dit gaat meestal in samenwerking met een developer.
Technische SEO punten oplossen kost vaak veel tijd, daarom is het goed om de punten op te delen in ‘must haves’ en ‘nice to haves’.
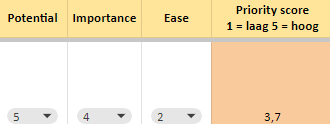
Bij SDIM prioriteren wij de actiepunten ook altijd a.d.h.v. het PIE-model. Daarbij geven we elke taak een score op basis van: potential, importance en ease.
‘Ease’ weegt ook mee omdat het bij technische SEO vaak verstandig is om eerst het ‘lowhanging fruit’ aan te pakken. Dit zijn meestal punten die makkelijk en snel op te lossen zijn, en dus ook weinig (development) kosten met zich meebrengen, maar die wel een groot verschil kunnen maken.
Wil je nu meer weten over SEO? Lees dan ook eens een van onze andere artikelen, we hebben er een heleboel. Of kom je er niet uit? Neem dan eens contact op, wij kijken graag naar de mogelijkheden voor jouw website.
Marius begon zijn carrière als marketing manager in Groningen, maar kwam er snel achter dat zijn passie bij SEO (en Haarlem) ligt. Zijn marketing brede visie zorgt ervoor dat zijn SEO strategieën goed samenwerken met andere facetten binnen marketing.





Reacties (0)